Overview
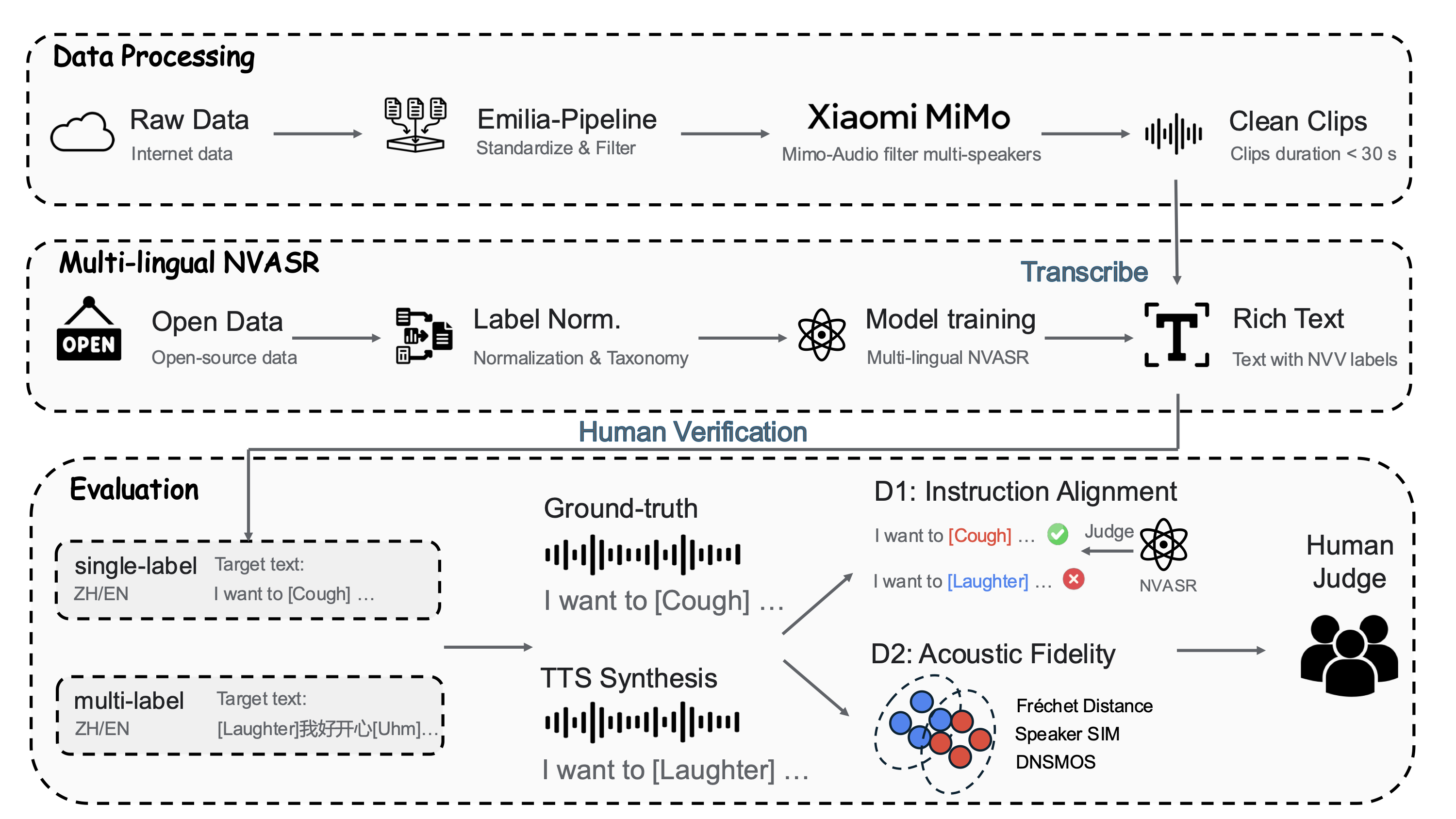
Figure 1. Overview of the NV-Bench pipeline — from raw data collection through multi-lingual NVASR transcription to dual-dimensional evaluation.
Audio Examples
Listen and compare: each example provides a prompt audio (reference speaker), the target text with NVV tags, ground-truth recording, and synthesized outputs from five TTS systems.
Functional Taxonomy
NVVs are organized into three functional levels based on communicative intent.
Level 1: Vegetative Sounds
Biological reflexes grounding speech in physical realism.
Level 2: Affect Bursts
Valenced vocalizations conveying emotion or instant reactions.
Level 3: Conversational Grunts
Interaction-management cues — filled pauses and prosodic particles.
Pipeline
Data Processing
565K clips (~1,560 hrs) filtered via Emilia-Pipeline & MiMo-Audio for single-speaker verification.
Multi-lingual NVASR
SenseVoice-Small fine-tuned on 6 datasets with unified label taxonomy.
Human Verification
10 annotators, Cohen's κ > 0.85 → 1,651 prompt-GT pairs (7.9 hrs).
Evaluation Protocol
Instruction Alignment
Can the model generate the specified NVV events at the correct positions?
- CER — Character Error Rate
- PCER — Paralinguistic CER
- OCER — Overall CER
Acoustic Fidelity
How realistic is the synthesized speech compared to real recordings?
- FAD / FD — Distribution Distance
- SIM — Speaker Similarity (WavLM)
- DNSMOS — Perceptual Quality